ALCCS
Code: CT75 Subject: DATA WAREHOUSING AND DATA MINING
 Time: 3 Hours
Max. Marks: 100
Time: 3 Hours
Max. Marks: 100
NOTE:
· Question 1 is compulsory and
carries 28 marks. Answer any FOUR questions from the rest. Marks are indicated against each question.
· Parts of a question should be
answered at the same place.
Q.1 a. Define Manhattan distance and Euclidean distance.
b. Explain
the difference between supervised and unsupervised learning with the help of a real world
example.
c. Discuss
data visualization?
d. Discuss
the different types of OLAP operations
e. Differentiate between data warehouse and
database.
f. Discuss
the measure support and confidence used in association rule mining.
g. Differentiate between clustering and
classification. (7
![]() 4)
4)
Q.2 a. Differentiate
between star schema, snowflake schema and fact constellation with the help of
examples.
b. Discuss Data extraction, Data transformation
and Data loading related to ETL. (9+9)
Q.3 a. Explain the ID3 Algorithm for decision trees.
b. Apply any hierarchical clustering algorithm
for clustering the following eight point. Determine the clusters with their
elements. The distance function is Euclidean distance
A1(2,10), A2(2,5), A3(8,4),
A4(5,8), A5(7,5), A6(6,4), A7(1,2),
A8(4,9). (8+10)
Q.4 a. What
is the ‘Apriori property’? How is it used by the APRIORI algorithm? What are the
drawbacks of the Apriori algorithm?
b. Given are the following eight transactions on
items {A,B,C,D,E}:
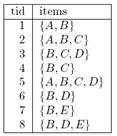
Use
the Apriori algorithm to compute all frequent item sets, and their support,
with minimum support as 3. Clearly indicate the steps of the algorithm. Give all generators of closed frequent item
sets and their closure. (8+10)
Q.5 a. Discuss
the steps involved in data Processing
b. Suppose we have the following points:
(1,1)
(2,4)
(3,4)
(5,8)
(6,2)
(7,8)
Use
k-Means algorithm (k=2) to find two clusters. The distance function is
Euclidean distance. Find 2 clusters using k-means clustering algorithm. Use (1,
1) and (2, 4) to form the initial clusters. (8+10)
Q.6 a. Discuss naïve Bayesian classification. Why is
it called “naïve”
b. Construct a bitmap index for the attributes
Brand and Color for the following relation cars
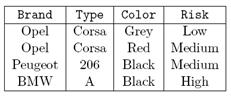
c. Discuss basic structure of a feed-forward
neural network. Discuss two major advantages of the back Propagation
algorithm in multi-layer neural network model. (6+4+8)
Q.7 Write short notes on (Any THREE):
(i) Outlier Analysis
(ii) Decision Support System
(iii) OLAP
(iv) Data Marts
(6 × 3)